SQL¶
With marimo, you can mix-and-match both Python and SQL. To create a SQL cell, you first need to install our SQL query engine of choice: duckdb.
pip install duckdb
This will enable SQL cells in your notebook. Once you’ve installed duckdb, you can create a SQL cell by right-clicking an Add Cell button and choosing “SQL cell”, by converting an empty cell to SQL via the cell context menu, or via the SQL button that appears when you mouse hover at the bottom of your notebook.
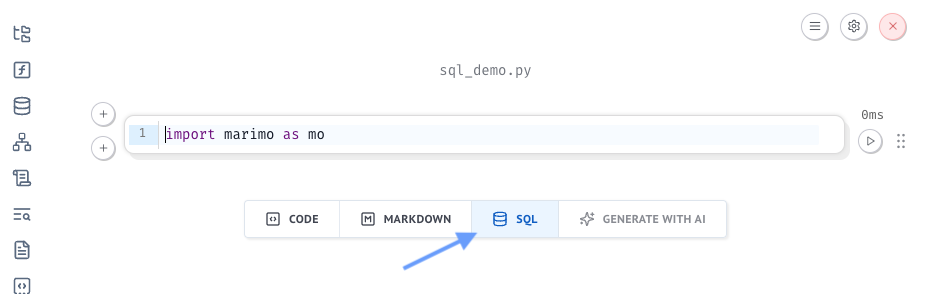
This creates a “SQL” cell for you, while in reality this is actually Python code. Since we store marimo files as pure Python files, the translated code looks like:
output_df = mo.sql(f"SELECT * FROM my_table LIMIT {max_rows.value}")
Notice that we have an output_df variable in the cell. This is a resulting Polars DataFrame (if you have polars installed) or a Pandas DataFrame (if you don’t). One of them must be installed in order to interact with the SQL result.
The SQL statement itself is an formatted string (f-string), so this means they can contain any valid Python code, such as the values of UI elements. This means your SQL statement and results can be reactive! 🚀
Reference a local dataframe¶
You can reference a local dataframe in your SQL cell by using the name of the Python variable that holds the dataframe. If you have a database connection with a table of the same name, the database table will be used instead.
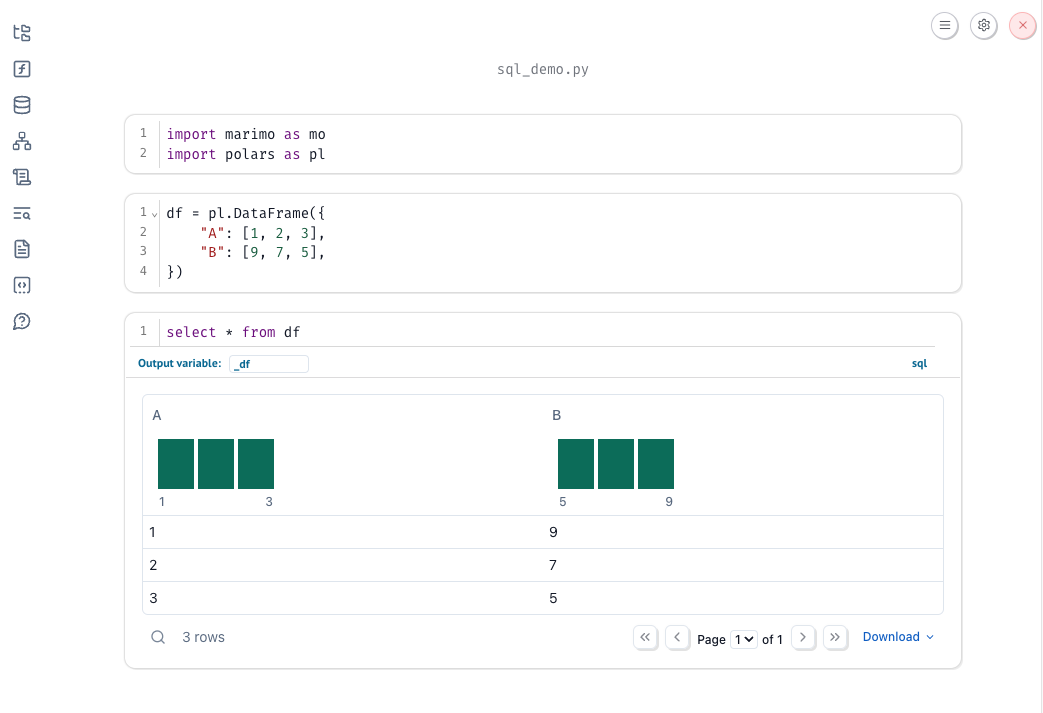
Since the output dataframe variable (_df) has an underscore, making it private, it is not referenceable from other cells.
Reference the output of a SQL cell¶
Defining a non-private (non-underscored) output variable in the SQL cell allows you to reference the resulting dataframe in other Python and SQL cells.
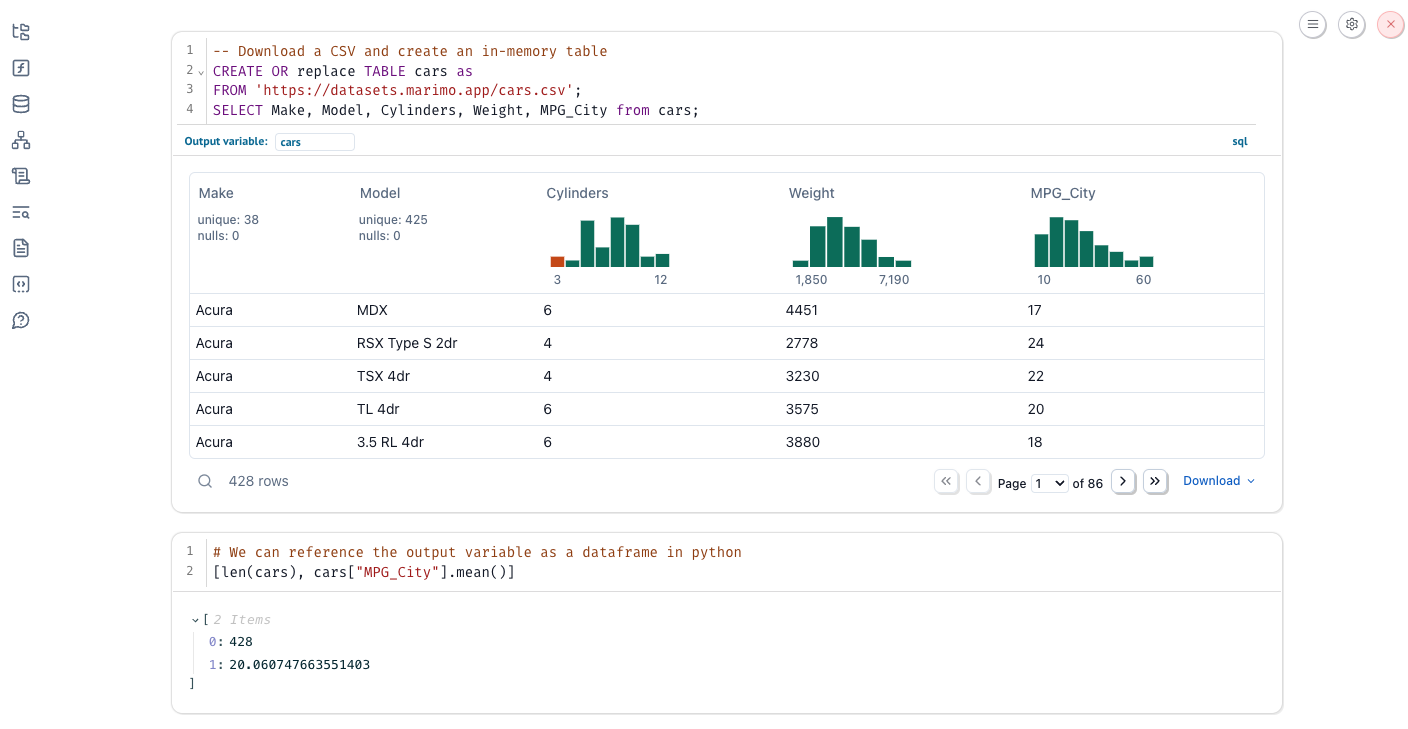
Querying files, databases, and APIs¶
In the above example, you may have noticed we queried an HTTP endpoint instead of a local dataframe. We are not only limited to querying local dataframes; we can also query files, databases, and APIs:
-- or
SELECT * FROM 's3://my-bucket/file.parquet';
-- or
SELECT * FROM read_csv('path/to/example.csv');
-- or
SELECT * FROM read_parquet('path/to/example.parquet');
For a full list you can check out the duckdb extensions.